Date :11/05/2026
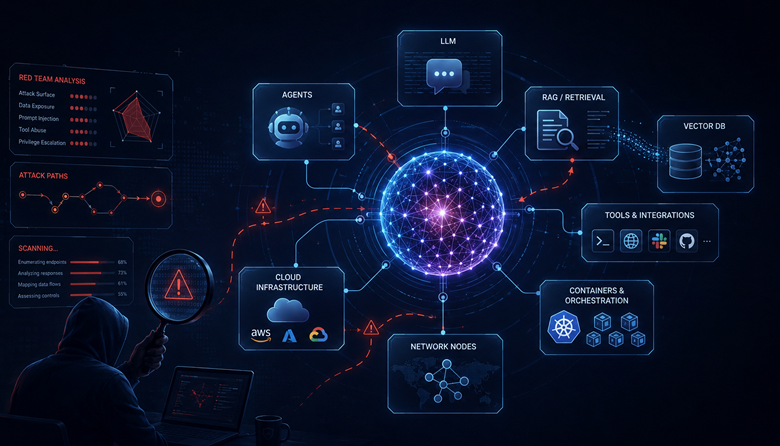
L’intelligence artificielle est sortie des démonstrations de laboratoire pour entrer dans les systèmes d’information réels : assistants internes, chatbots publics, pipelines RAG, agents autonomes, outils de développement, workflows métier, bases vectorielles, serveurs MCP et intégrations cloud.
Pour les équipes sécurité, ce changement est loin d’être cosmétique. Un système IA ne se teste pas exactement comme une application web classique ou un service backend traditionnel. Bien sûr, les vulnérabilités habituelles existent toujours : mauvaises configurations, secrets exposés, IAM trop large, containers mal durcis, Active Directory vulnérable. Mais l’IA ajoute une couche supplémentaire : le comportement.
Attaquer une IA, ce n’est pas seulement casser une machine. C’est aussi influencer ce qu’elle croit, ce qu’elle récupère, ce qu’elle transmet, ce qu’elle décide et parfois ce qu’elle fait.
Le vrai risque n’est pas toujours :
"peut-on compromettre le modèle ?"
Mais plutôt :
"que peut faire le système complet si le modèle est manipulé ?"Pourquoi le pentest IA change la perspective
Dans un pentest classique, on cherche souvent à obtenir un accès, voler ou lire des données, escalader les privilèges, maintenir un accès ou pivoter vers une zone plus sensible. Ces objectifs restent valables dans les environnements IA. Mais ils ne suffisent plus.
Un système IA peut être vulnérable sans qu’un attaquant obtienne immédiatement un shell ou un compte administrateur. Il peut être vulnérable parce qu’il accepte une source non fiable comme contexte, parce qu’il fait confiance à un outil trop permissif, parce qu’il récupère un mauvais document dans un RAG, ou parce qu’un agent agit avec plus de droits que l’utilisateur qui l’a sollicité.
On passe donc d’une logique purement binaire à une analyse plus nuancée. Une réponse IA peut être partiellement correcte, subtilement trompeuse, dangereuse dans un contexte précis, ou exploitable uniquement lorsqu’elle est chaînée avec un outil, une mémoire ou un workflow métier.
Le red teaming IA consiste à tester cette chaîne complète : modèle, contexte, outils, données, agents, infrastructure et décisions aval.
La pile IA moderne : bien plus qu’un chatbot
Une application IA d’entreprise n’est presque jamais un simple formulaire connecté à un modèle. Derrière une interface de chat apparemment simple, on peut trouver une pile complète :
- Interface utilisateur
- API gateway
- Orchestrateur d’agents
- Pipeline RAG
- Base vectorielle
- Serveur d’inférence
- Outils appelables par le modèle
- Serveurs MCP
- Stockage objet
- Model registry
- IAM cloud
- Kubernetes
- Pipelines CI/CD
- Logs de prompts et de réponses.
Chaque couche ajoute une surface d’attaque. Le modèle n’est qu’un composant. La surface réelle est l’écosystème qui permet au modèle de recevoir du contexte, d’appeler des outils, de lire des documents et parfois de déclencher des actions.
Un LLM isolé répond.
Un agent outillé agit.
Un système IA intégré influence un workflow.Reconnaissance IA : cartographier avant de tester
La reconnaissance est une phase essentielle. Les systèmes IA laissent souvent fuiter des informations utiles avant même qu’une attaque réelle ne commence.
On cherche notamment à identifier :
- Le modèle utilisé
- Le framework d’orchestration
- L’existence d’un RAG
- La base vectorielle
- Les outils disponibles
- Les endpoints backend
- Les serveurs MCP
- Les workflows multi-agents
- Les défenses et guardrails
- Les logs et mécanismes de détection.
La reconnaissance passive peut passer par les headers HTTP, la documentation publique, les fichiers JavaScript, les dépôts Git, les offres d’emploi, les profils publics ou les messages d’erreur.
La reconnaissance active, elle, consiste à interagir prudemment avec le système : poser des questions de test, observer les citations RAG, demander des capacités non sensibles, détecter la présence d’outils ou comprendre comment le modèle réagit face à certaines contraintes.
L’objectif n’est pas encore d’exploiter. L’objectif est de reconstruire la cible.
Les frameworks à connaître : OWASP, MITRE ATLAS et AI Kill Chain
Même si le red teaming IA reste un domaine jeune, il ne faut pas le traiter comme une discipline sans cadre. Plusieurs référentiels permettent déjà de structurer les tests, de nommer les techniques et de relier les vulnérabilités IA à des risques compréhensibles par les équipes sécurité.
Trois frameworks sont particulièrement utiles pour aborder sérieusement les systèmes IA :
- OWASP Top 10 for LLM Applications
- MITRE ATLAS
- NVIDIA AI Kill Chain.
OWASP Top 10 for LLM Applications
L’OWASP Top 10 for LLM Applications est probablement le point d’entrée le plus accessible pour structurer les risques applicatifs liés aux LLM, aux RAG et aux agents. Il permet de classer les vulnérabilités par grandes familles : prompt injection, fuite d’informations sensibles, supply chain, data and model poisoning, improper output handling, excessive agency, system prompt leakage, faiblesses liées aux embeddings et bases vectorielles, misinformation ou encore consommation non maîtrisée de ressources.
Pour un pentest, OWASP sert surtout de checklist de risques. Il aide à vérifier que l’on ne se limite pas au jailbreak du modèle, mais que l’on couvre aussi les outils, les données, les sorties, les intégrations, la supply chain et l’infrastructure autour de l’application IA.
OWASP LLM Top 10 = quels risques applicatifs tester ?MITRE ATLAS
MITRE ATLAS joue un rôle différent. Là où OWASP aide à classer les risques applicatifs, ATLAS sert à décrire les tactiques et techniques adverses contre les systèmes IA. C’est l’équivalent conceptuel de MITRE ATT&CK, mais appliqué aux systèmes d’intelligence artificielle.
ATLAS est utile pour nommer précisément les techniques, construire une matrice d’attaque, produire une cartographie offensive et aligner les équipes red team, blue team et gouvernance IA sur un vocabulaire commun.
MITRE ATLAS = comment nommer et organiser les techniques adverses IA ?NVIDIA AI Kill Chain
L’AI Kill Chain de NVIDIA apporte une autre perspective : celle de la progression dans le temps. Elle aide à représenter une attaque IA comme une chaîne plutôt que comme une vulnérabilité isolée.
C’est particulièrement utile dans des scénarios de red team complets, où une faille IA n’est que le premier maillon d’un enchaînement plus large : reconnaissance, empoisonnement, détournement, persistance, impact.
NVIDIA AI Kill Chain = comment l’attaque IA progresse dans le temps ?Comment les utiliser ensemble ?
| Framework | Question principale | Usage en pentest IA |
|---|---|---|
| OWASP Top 10 for LLM Applications | Quels risques tester ? | Checklist applicative et classification des findings |
| MITRE ATLAS | Comment nommer les techniques adverses ? | Taxonomie offensive et mapping red/blue team |
| NVIDIA AI Kill Chain | Comment l’attaque progresse-t-elle ? | Chaînage d’attaque et threat modeling opérationnel |
OWASP = quoi tester
MITRE ATLAS = comment classifier
AI Kill Chain = comment chaînerAgents IA : le vrai changement de risque
Un chatbot classique reçoit une question et renvoie une réponse. Un agent IA va plus loin. Il peut raisonner en plusieurs étapes, choisir un outil, lire un fichier, interroger une base, appeler une API, écrire dans une mémoire ou déléguer à un autre agent.
C’est ce passage de la réponse à l’action qui change le niveau de risque.
Les composants critiques d’un agent sont généralement :
- Le LLM
- Le system prompt
- Les outils
- La mémoire
- Les guardrails.
Le problème vient souvent du manque de séparation stricte entre données et instructions. Un modèle reçoit dans un même contexte des éléments de confiance différente : message utilisateur, prompt système, sortie d’outil, mémoire, documents RAG, résultats d’autres agents.
Si ces éléments sont mal séparés, une donnée non fiable peut être interprétée comme une instruction légitime.
Utilisateur → Agent → Outil → Résultat outil → LLM → Action
Chaque flèche est une frontière de confiance potentielle.Prompt injection : directe, indirecte et persistante
Les attaques par prompt injection consistent à manipuler les instructions traitées par le modèle. Il ne faut pas les réduire aux célèbres formulations du type “ignore les instructions précédentes”. En environnement réel, les attaques sont souvent plus discrètes.
On distingue principalement :
- Direct prompt injection : l’instruction hostile est fournie directement par l’utilisateur
- Goal hijacking : l’objectif de l’agent est détourné progressivement
- Indirect prompt injection : l’instruction vient d’un document, d’une page web, d’un ticket, d’un email ou d’un résultat d’outil
- Memory poisoning : l’influence est stockée dans une mémoire réutilisée plus tard
- Tool response poisoning : la sortie d’un outil est utilisée pour influencer le modèle.
L’indirect prompt injection est particulièrement importante, car elle persiste souvent au-delà d’une simple conversation. Un document empoisonné peut affecter plusieurs utilisateurs, plusieurs agents ou plusieurs sessions.
Une injection directe attaque une conversation.
Une injection indirecte attaque une source de contexte.La défense doit donc traiter les documents, sorties d’outils, mémoires et messages inter-agents comme des données non fiables par défaut.
RAG : la sécurité du contexte
Le RAG, ou Retrieval-Augmented Generation, permet à un modèle de répondre à partir de documents externes. C’est très utile pour intégrer des informations internes, récentes ou métier. Mais cela transforme la base documentaire en surface d’attaque.
Un pipeline RAG typique inclut :
- Ingestion documentaire
- Extraction de texte
- Chunking
- Embeddings
- Stockage vectoriel
- Metadata store
- Retrieval
- Reranking
- Sélection Top-K
- Construction du prompt augmenté
- Génération
- Filtrage de sortie.
Le point critique est le choix du contexte injecté dans le modèle.
Attaquer un RAG, c’est attaquer la manière dont le système choisit
ce que le modèle va lire.Les attaques RAG incluent le knowledge base poisoning, le retrieval hijacking, les fuites de métadonnées, les contournements d’autorisation, les bypass de filtres de sortie et le slow poisoning.
Le retrieval hijacking consiste à faire remonter un chunk contrôlé dans les meilleurs résultats afin qu’il soit injecté dans le contexte du modèle. Si ce chunk contient une instruction et que le système ne distingue pas correctement contexte et instruction, le modèle peut être manipulé.
Le point souvent oublié est la différence entre pertinence et confiance.
Un document peut être très pertinent pour une requête,
mais non fiable, obsolète, empoisonné ou non autorisé.Embeddings : ce ne sont pas des hashes
Les embeddings sont souvent mal compris. Beaucoup d’équipes les considèrent comme des artefacts techniques peu sensibles. C’est une erreur.
Un embedding n’est pas un hash cryptographique. Un hash est conçu pour masquer le contenu et changer complètement au moindre changement d’entrée. Un embedding, au contraire, est conçu pour préserver une proximité de sens.
Un hash cache le sens.
Un embedding encode le sens.Cela ouvre plusieurs risques :
- Attribute inference : prédire le type ou la sensibilité d’un contenu
- Membership inference : déterminer si une information existe dans la base
- Embedding inversion : tenter de reconstruire du texte à partir d’un vecteur
- Metadata leakage : fuite par noms de fichiers, tags, IDs, scores ou chemins internes.
Une reconstruction parfaite n’est pas toujours réaliste, surtout pour des secrets aléatoires à forte entropie. Mais une reconstruction partielle peut suffire à révéler un sujet, une procédure, un projet ou la présence d’une information sensible.
Les bases vectorielles doivent donc être protégées comme des bases sensibles : authentification forte, séparation par tenant, contrôle d’accès avant retrieval, minimisation des métadonnées, chiffrement, logs d’accès et limitation des scores exposés.
MCP et outils : le modèle hérite de capacités externes
Le Model Context Protocol, ou MCP, permet de connecter un LLM à des outils et sources externes. C’est puissant, mais cela agrandit considérablement le blast radius du modèle.
MCP peut exposer :
- Des outils filesystem
- Des outils Git
- Des bases SQL
- Des intégrations Slack, GitHub ou GitLab
- Des notes internes
- Des resources
- Des prompts
- Des schemas d’outils.
MCP est souvent auto-documentant : il décrit les outils, leurs paramètres et leurs sorties. Ce qui aide le modèle aide aussi l’attaquant pendant l’énumération.
Les risques principaux sont :
- Schema extraction
- Cross-tool correlation
- Permission abuse
- Constraint bypass
- Tool poisoning
- Tool shadowing
- UI rendering abuse.
Le tool poisoning consiste à manipuler la description, le schema ou la logique d’un outil. C’est dangereux parce que la description d’un outil influence directement le choix et le comportement du modèle.
Le tool shadowing consiste à créer un outil qui ressemble à un outil légitime. Si le modèle ne vérifie pas l’identité et l’origine de l’outil, il peut appeler le mauvais composant.
Un outil MCP doit être traité comme une extension privilégiée du LLM.
Sa description, son schema, sa logique et ses permissions font partie de la surface d’attaque.Systèmes multi-agents : la confiance devient la surface d’attaque
Dans un système multi-agent, plusieurs agents communiquent, délèguent des tâches et se transmettent du contexte. Cela ajoute des surfaces nouvelles : messages inter-agents, handoffs, registres d’agents, Agent Cards, workflows distribués et différences de privilèges.
Les architectures courantes incluent :
- Orchestrator / hub-and-spoke : un agent central distribue les tâches
- Peer-to-peer / mesh : les agents communiquent directement
- Hierarchical / tree : des agents superviseurs contrôlent des agents subordonnés
- Pipeline / chain : chaque agent transmet son résultat au suivant.
Le pipeline est particulièrement intéressant : un contenu injecté tôt peut voyager dans la chaîne et être traité plus tard par un agent plus privilégié.
Le risque majeur est le confused deputy. Un utilisateur ou agent faiblement privilégié peut influencer un agent plus privilégié pour qu’il agisse à sa place.
Utilisateur faible privilège
→ agent support
→ agent privilégié
→ action ou donnée normalement inaccessibleDans ces architectures, tous les messages inter-agents doivent être considérés comme non fiables tant qu’ils ne sont pas authentifiés, autorisés et validés.
Supply chain IA : code, données et comportement
La supply chain IA est plus large qu’une supply chain logicielle classique. Elle inclut le code, mais aussi les modèles, datasets, tokenizers, adapters LoRA, checkpoints, serveurs MCP, notebooks, prompts et pipelines.
Deux grandes familles d’attaques existent.
La première vise l’exécution de code. Elle peut passer par un package compromis, un notebook, un serveur MCP, du code distant chargé avec trop de confiance ou des formats de sérialisation dangereux.
La seconde vise le comportement. Pas besoin d’exécuter du code : il suffit parfois de modifier les données d’entraînement, un adapter, un tokenizer ou les poids du modèle.
SafeTensors réduit le risque d’exécution de code à la désérialisation, mais ne garantit pas qu’un modèle est sain.
SafeTensors peut rendre un modèle plus sûr à charger.
Il ne garantit pas qu’il est sûr à utiliser.Un modèle peut être sûr à charger, mais backdooré au niveau comportemental.
La défense passe par la provenance, les signatures, les hashes, le version pinning, les AI-BOM, la revue des datasets, les tests comportementaux, la sandbox et le contrôle strict des artefacts externes.
Infrastructure IA : cloud, IAM, containers et Kubernetes
Les systèmes IA en production reposent souvent sur une infrastructure complexe : endpoints d’inférence, buckets de données, artefacts de modèles, feature stores, model registries, IAM roles, secrets managers, containers, Kubernetes, notebooks, MLflow et jobs GPU.
Une faille applicative IA peut devenir critique si elle ouvre un chemin vers cette infrastructure.
Dans le cloud, l’IAM est central. Des permissions trop larges, des rôles partagés, des chaînes d’assume-role mal maîtrisées ou des buckets mal cloisonnés peuvent transformer un accès limité en compromission large.
Dans Kubernetes, les points critiques sont les service accounts, RBAC, secrets, ConfigMaps, pods, volumes et workloads GPU. Un pod compromis donne souvent accès à l’identité Kubernetes du pod. Si cette identité est trop privilégiée, elle devient un pivot.
Les ConfigMaps ne sont pas censées contenir de secrets, mais elles révèlent souvent la topologie : endpoints internes, noms de buckets, URIs MLflow, noms de services ou paramètres de jobs.
L’infrastructure IA est souvent le chemin le plus court entre une faille applicative
et la compromission des modèles, données ou workloads.Threat modeling IA : transformer l’incertitude en décision
Sur un vrai engagement, on ne commence presque jamais avec un schéma complet. On dispose de fragments : scope, OSINT, documentation partielle, erreurs techniques, endpoints, traces de frameworks, comportements observés.
Le threat modeling IA consiste à transformer ces fragments en décisions.
Les outils importants sont :
- Target reconstruction
- Assumption register
- Facts / assumptions / unknowns
- Crown jewels
- Trust boundaries
- Trust zones
- Escalation paths
- Rules of Engagement
- Decision matrix
- Attack intelligence brief.
L’assumption register évite de confondre une hypothèse avec une preuve. L’absence d’information n’est jamais une preuve de vulnérabilité.
Les crown jewels doivent être classés selon leur valeur de pivot : ce qu’ils permettent ensuite. Un token d’agent, un tool schema MCP ou une règle de détection peuvent avoir une valeur offensive très élevée.
Les trust boundaries IA sont parfois techniques, mais parfois seulement “inference-based”. Le modèle fait confiance à une source parce qu’elle semble pertinente, pas parce qu’une politique d’autorisation l’a validée.
La pertinence n’est pas une preuve d’autorisation.
La plausibilité n’est pas une preuve de confiance.Du chatbot au domain takeover : le capstone réaliste
Un engagement IA réaliste ne s’arrête pas au LLM. Un capstone typique commence par une surface IA exposée, par exemple un chatbot public outillé, puis progresse vers des couches plus classiques.
Chatbot public
→ outil backend
→ premier accès ou preuve équivalente
→ pivot interne
→ knowledge base / RAG / shares
→ credentials
→ lateral movement
→ Active Directory
→ preuve d’impact domaineÀ un certain stade, on quitte partiellement l’IA pure pour revenir à de la red team infra classique : réseau interne, gateways, RDP/RDS, partages, credentials, Active Directory.
Ce n’est pas une incohérence. C’est précisément le message du capstone.
Une surface IA peut être le premier maillon d’une chaîne de compromission complète.Le risque réel n’est pas seulement que le chatbot réponde mal. Le risque est qu’il permette d’atteindre un outil backend, qui permet d’obtenir un premier accès, qui permet de pivoter, qui permet de trouver des secrets, qui permet d’escalader vers le domaine.
Mesures de défense prioritaires
Pour sécuriser un environnement IA, il ne suffit pas d’ajouter un filtre de prompt. Il faut traiter l’IA comme un système distribué, connecté à des données, outils, identités et infrastructures.
Actions de remédiation
- Séparer strictement les données et les instructions.
- Traiter documents, sorties d’outils, mémoires et messages inter-agents comme non fiables.
- Limiter les permissions des agents et outils au strict nécessaire.
- Valider les appels d’outils côté serveur.
- Interdire les requêtes backend arbitraires générées par le modèle.
- Appliquer les permissions avant retrieval dans les pipelines RAG.
- Marquer les sources RAG par niveau de confiance.
- Protéger les bases vectorielles comme des bases sensibles.
- Signer, valider et versionner les tools MCP.
- Journaliser les appels outils et handoffs inter-agents.
- Auditer datasets, modèles, adapters et tokenizers.
- Appliquer le moindre privilège sur IAM, Kubernetes et comptes de service.
- Surveiller les logs de prompts, mais éviter d’y stocker des secrets.
- Définir des preuves non destructives dans les Rules of Engagement.
Quick win : tester les frontières de confiance
Si vous devez commencer quelque part, commencez par les frontières de confiance. Ce sont souvent elles qui cassent.
Posez-vous les questions suivantes :
- Quelles données externes entrent dans le contexte du modèle ?
- Quels outils le modèle peut-il appeler ?
- Qui valide les paramètres envoyés aux outils ?
- Le RAG distingue-t-il pertinence et confiance ?
- Les documents utilisateur peuvent-ils influencer les réponses officielles ?
- Les messages inter-agents sont-ils authentifiés et autorisés ?
- Les embeddings et métadonnées sont-ils protégés ?
- Les agents disposent-ils de comptes de service trop larges ?
- Les sorties du modèle déclenchent-elles des actions automatiques ?
- Les logs contiennent-ils des prompts, secrets ou données sensibles ?
Une grande partie du risque IA se situe à ces points de passage.
Conclusion
Le pentest et le red teaming des systèmes IA ne consistent pas simplement à “jailbreak” un chatbot. C’est une discipline plus large, qui combine sécurité applicative, cloud, infrastructure, supply chain, données, agents, RAG, embeddings, outils et threat modeling.
Les frameworks comme OWASP Top 10 for LLM Applications, MITRE ATLAS et l’AI Kill Chain permettent de structurer cette démarche. Ils évitent de traiter la sécurité IA comme une collection de cas particuliers et fournissent un vocabulaire commun pour prioriser, tester, documenter et remédier.
Un système IA moderne est un système distribué. Le modèle n’est qu’un composant. Les vraies failles apparaissent souvent aux frontières : entre utilisateur et modèle, document et contexte, modèle et outil, agent et autre agent, RAG et base documentaire, outil et infrastructure, sortie IA et action automatisée.
La question centrale n’est donc pas seulement :
Le modèle répond-il correctement ?Mais plutôt :
À quoi le modèle a-t-il accès ?
À qui fait-il confiance ?
Que peut-il déclencher ?
Qui consomme ses sorties ?
Et que se passe-t-il si son comportement est manipulé ?C’est là que se situe le vrai risque.
Une faille IA devient critique lorsqu’elle s’insère dans une chaîne complète : contexte manipulé, outil trop permissif, secrets exposés, pivot interne, infrastructure mal configurée et escalade classique.
Pour tester ces environnements, il faut donc penser comme un red teamer, mais avec une obsession supplémentaire : la confiance accordée au contexte.
Dans les systèmes IA, le contexte est une surface d’attaque.Et pour les défendre, un principe simple reste valable :
Ne jamais faire confiance à une donnée simplement parce qu’elle est pertinente,
bien formulée ou produite par un composant interne.Source : synthèse pédagogique et analyse ADNC sur le pentest et red teaming des systèmes IA.



